2022. 6. 29. 08:25ㆍData Science/with Python(Numpy, Pandas …ect.)
Array Operation (like vector) → Universal Function
vector처럼 사용할 수 있다는 것이 가장
큰 특징이자 Numpy를 이용하는 이유이다.
또한 데이터 분석에서 쓰이는 대표적인
라이브러리들(scipy, matplotlib, scikit-learn,
pandas, tensorflow, pytorch 등) 대부분이
numpy array를 사용하고, 데이터 분석은
99.9% 데이터를 벡터로 표현하여 분석하기
때문에 매우 중요하다.
1. 벡터 v1, v2 생성하기
v1 = np.array((1, 2, 3))
v2 = np.array((4, 5, 6))이때 주의할 건 v1 = (1, 2, 3) 가 아니라
앞에 꼭' np.array'를 붙여줄 것!
붙이지 않으면 그건 단순한 튜플이다.
2. 튜플로 더하기 연산 해보기
t1 = (1, 2, 3)
t2 = (4, 5, 6)보통 이런 유형의 예제는 리스트를 많이
다루는데 리스트던 튜플이던 상관은 없다.
이번에는 비슷하게 생긴 튜플로 진행~
3. vector addition
t1 + t2
결과값 : array([5, 7, 9])벡터는 같은 자리 원소끼리 더하기 때문에
더하기 연산을 하면 위와 같이 나온다.
이런 계산법을 elementwise edition이라고 한다.
tuple이나 list였다면 단순히 이어 붙인
(1, 2, 3, 4, 5, 6)이 나왔을 것이다.
4. vector subtraction
t1 - t2
결과값 : array([-3, -3, -3])만약 우리가 이걸 numpy 식, 벡터로
계산하지 않고 기존의 코드를 활용한다면
zip은 아직 배운 적이 없다만
다음과 같이 나온다.
L = []
for x, y in zip(v1, v2):
a = x - y
L.append(a)
L
5. (not vector operation) elementwise multiplication
v1 * v2
결과값 : array([4, 10, 18])벡터엔 곱셈이란 개념이 따로 존재하지
않아 기존에 우리가 배웠던 방식을 따른다.
6. (not vector operation) elementwise division
v1 / v2
결과값 : array([0.25, 0.4, 0.5])나눗셈 역시 위와 같은 이유로
기존 방식대로 연산된다고 생각하면 된다.
7. dot product
v1 @ v2
결과값 : 32
# 1x4 + 2x5 + 3x6 = 32내적은 @ 기호를 활용한다.
참고로 v1과 v2의 원소의 개수가 같아야
Error 없이 연산을 진행할 수 있다.
예를 들어 위 예문에서 v2의 원소 하나를
지워 v2 = np.array((4, 5))로 두고 진행했다면
더하기 연산자부터 broadcast를 한 수 없다며
Error를 내보냈을 것이다. elementwise edition
계산법을 가지기 때문에 원소의 개수를
일치 시켜줘야 한다.
Broadcast
서로 크기가 다른 numpy array를 연살할 때,
자동으로 연산을 전파(broadcast)햊는 기능으로
행렬곱 연산 할 때 편리하다.
arr1 = np.array([[1, 2, 3],
[4, 5, 6]])
arr2 = np.array([7, 8, 9])이렇게 생긴 arr1이 있다고 하자.
arr1.shape
결과값 : (2, 3)2행 3열, 2x3 행렬이란 뜻으로
2차원 array에 원소가 2개있는데
각 원소에 3개씩 들어가 있다고
해석할 수 있다.
arr1 + arr2
결과값 : array (([8, 10, 12],
[11, 13, 15]))아까는 안 되지 않았나 의아할 수도
있을텐데 연산을 해줄 원소의 개수가
동일하면 덧셈도 곱셈도 가능하다.
arr1 * arr2
결과값 : array (([7, 16, 27],
[28, 40, 54]))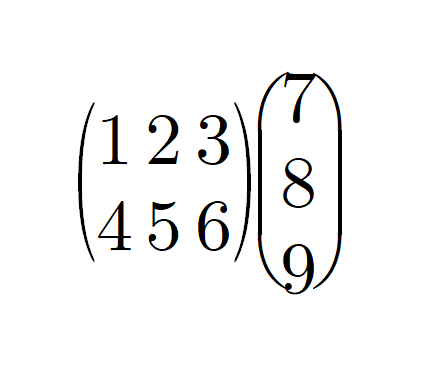
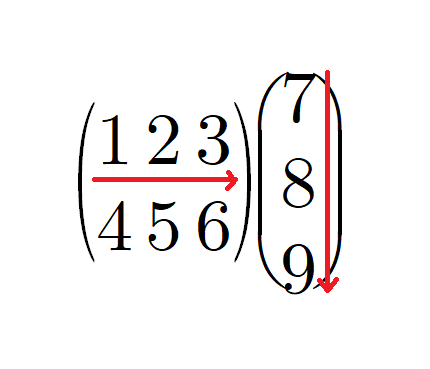
행렬 곱셈 방식을 보면 원소 개수를
맞추란 의미가 좀 더 와닿을 것 같아 그려봤다.
arr1에 arr가 아닌 숫자를 곱한면
vector scalar multiplication이므로
(10이 벡터가 아닌 스칼라 값이라는 뜻.
스칼라는 방향을 가지지 않고 크기만 있다.)
arr1 * 10
결과값 : array (([10, 20, 30],
[40, 50, 60]))이와 같은 결과값을 낸다.
arr1 * arr1
결과값 : array (([1, 4, 9],
[16, 25, 36]))제곱도 가능하다.
Universal Functions
numpy array는 하나의 함수를 모든 원소에
자동으로 적용해주는 기능을 제공하는데 그
기능의 이름이 universal function이다.
이 기능 덕분에 모든 원소에 같은 작업을
처리할 때 매우 빠른 속도로 작업이 가능하다.
arr1 = np.array([1, 2, 3] , dtype=float)만약 arr1의 타입을 실수로 바꾸고 싶다고 해보자.
그럼 위와 같이 np.array를 선언할 때 뒤에
dtype을 붙여서 바꿔줄 수도 있다.
arr1 = np.array([1, 2, 3])
arr1 / 1하지만 좀 더 간단하게 이렇게 해줄 수도 있다.
모든 원소를 역수 취하고 싶다면 어떻게 해야할까?
1 / arr1이렇게 간단히 뒤집기만 하면 된다.
각 원소에 1 / 라는 operation을 모두
적용하는 연산이 된다.
더하기는 예상하는 대로 arr1 + 2 라고
입력하면 모든 원소에 각각 2를 더하는
operation이 적용된다.
'Data Science > with Python(Numpy, Pandas …ect.)' 카테고리의 다른 글
| Numpy Array Functions (0) | 2022.06.29 |
|---|---|
| Numpy Indexing+Masking (0) | 2022.06.29 |
| Numpy Array 만들기 (0) | 2022.06.28 |
| Numpy 기본 개념 (0) | 2022.06.28 |
| 아나콘다(ANACONDA) 및 Jupyter Notebook (0) | 2022.06.27 |