2022. 7. 3. 22:18ㆍData Science/with Python(Numpy, Pandas …ect.)
Scatterplot
lineplot과 비슷하게 x, y에 대한
데이터의 전체적인 분포를 확인하는 plot이다.
차이점이 있다면 lineplot이 x,y 관계를
선으로 그었다면 scatterplot은 물감을
뿌리듯 흩뿌려서 나타내준다.
산포도, 산점도라고도 한다.
그렇다 보니 lineplot은 경향성에
초점을 둔다면, scatterplot은
전체적인 데이터가 퍼져있는
모양에 중점을 둔다.
# penguin 데이터에 scatterplot을 출력.
## 1. 질량과 부리 길이 관계 - 종별 차이
sns.scatterplot(data=penguins, x="body_mass_g", y="flipper_length_mm", hue="species")
## 2. 부리 길이와 깊이(두께) 관계 - 성별 차이
sns.scatterplot(data=penguins, x="bill_length_mm", y="bill_depth_mm", hue="sex")

Pairplot
scatterplot을 무엇과 무엇에 주느냐에
따라 다 찍어주는 것이 pairplot이다.
각 feature에 대해 계산된 모든 결과를
보여주기 때문에 feature가 많은 경우에는
사용하기 적합하지 않다.
pairplot은 기본적으로 알아서 feature들
간의 찾아주기 때문에 x, y를 일일이
지정해줄 필요는 없다. 해줘도 되지만
필수조건이 아니란 뜻이다.
sns.pairplot(data=penguins, hue="species")예를 들어 위와 같이 코드를 넣어 돌리면
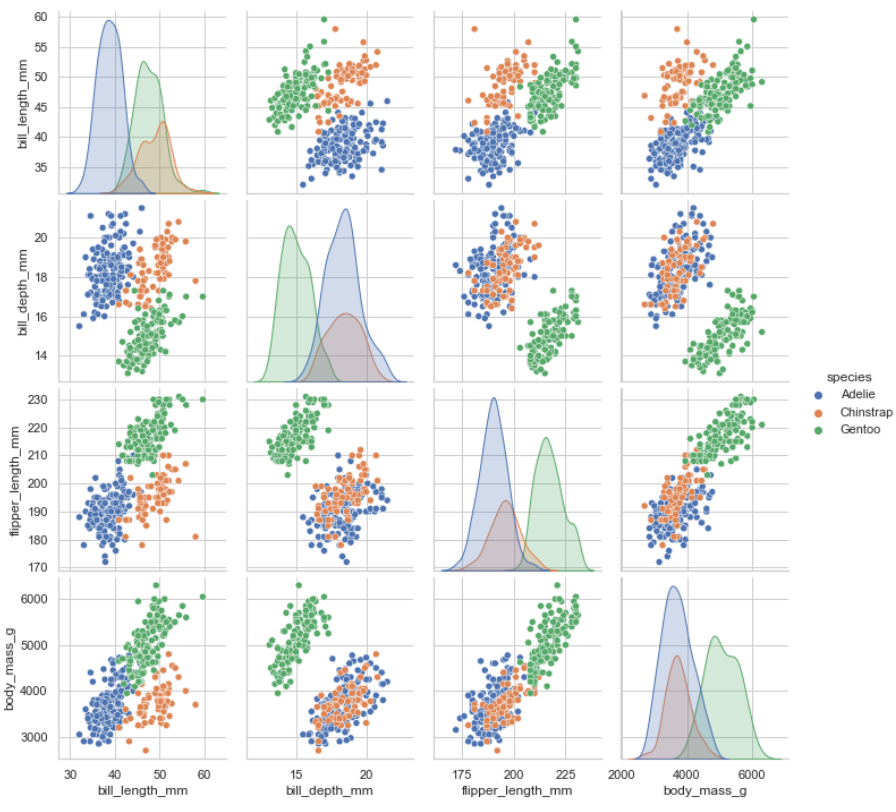
이렇게 4가지 feature를 조합하여
모든 경우에 대해 종별로 나타내 주는
것을 확인할 수 있다.
그렇기 때문에 feature가 너무 많으면
돌리는 시간도 오래 걸리거니와
일일이 확인하고 비교하는 것도 무리가
있다. 그래서 보통 freature가 적을 때
사용하거나 많은데 확인을 하고 싶을 경우
feature를 뽑아서 적게 하여 볼 수도 있다.
Heatmap
pairplot과 비슷한 느낌의 plot인데
feature가 많은 때 유용하다. 앞서 말했듯
feature가 200개만 돼도 pairplot을 돌렸을 때
figure는 4만개가 나올 거다. 현실적으로
무리라고 생각한다.
이런 경우는 정보를 요약하여 일목요연하게,
정보 차이를 확연하게 눈에 보여주는 것이
더 효율적이고 필요할 것이다.
이처럼 정보 간의 차이를 색의 차이로 표현해
한눈에 확인할 수 있는 기법이 바로 Heatmap이다.
말 그대로 heatmap이기 때문에, 열화상카메라로
사물을 찍은 것처럼 정보의 차이를 보여주는데
수치 차이→색 차이로 나타나는 것이기 때문에
Heatmap기법을 사용하기 위해서는
수치 데이터가 있어야 한다.
가장 많이 사용하는 기법이 상관계수를
행렬로 나타내어 색칠하는 법이다.
-내가 LOL 데이터 분석 할 때 썼던 기법-
그럼 우선 Correlation matrix를 만들어야
하는데 2가지 방법이 있다.
Numpy에서 np.corr을 쓰거나 그걸 확장해서
DataFrame에서도 사용 가능하다.
그래서 Pandas에서 바로 만들면 된다.
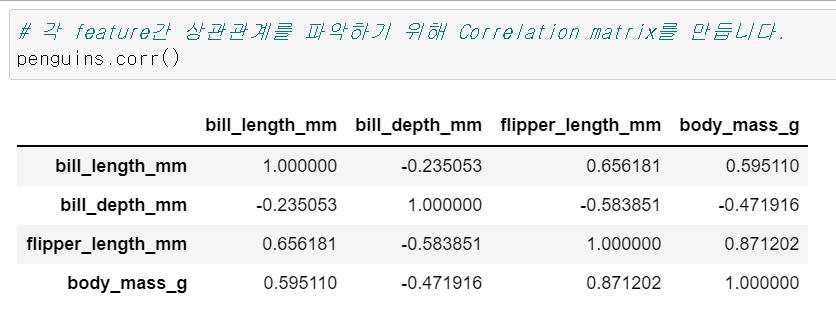
이걸 이제 heatmap에 넣어준다.
# Correlation matrix 생성
corr=penguins.corr()
# penguin 데이터에 heatmap을 출력
sns.heatmap(corr)
'Data Science > with Python(Numpy, Pandas …ect.)' 카테고리의 다른 글
| 공공 데이터 분석 프로젝트(커피 전문점) 02 (0) | 2022.07.05 |
|---|---|
| 공공 데이터 분석 프로젝트(커피 전문점) 01 (0) | 2022.07.05 |
| Seaborn : lineplot&pointplot (0) | 2022.07.03 |
| Seaborn : boxplot&violinplot (0) | 2022.07.03 |
| Seaborn : barplot&countplot (0) | 2022.07.03 |