2022. 7. 9. 18:47ㆍData Science/with Python(Numpy, Pandas …ect.)
데이터 전처리
import pandas as pd
from pandas import DataFrame
from pandas import Series
import matplotlib.pyplot as plt네이버 검색광고 데이터를
read_excel 함수를 사용하여 파이썬에
불러와 DataFrame의 열 단위 수치연산
및 데이터 타입 다루는 것을 목표로 한다.
# window의 경우 경로인식에러 발생
df=pd.read_excel('C:\Users\user\OneDrive\Desktop\marketing\NAVER.xls')read함수를 이용하여 데이터를 불러올 때
탐색창에 있는 주소를 그대로 복붙해오면
Error를 발생하는데 그 이유가 윈도우
탐색창은 \를 사용하고, 파이썬은 /을
사용하기 때문인데 해결방법은 다음과 같다.
# 방법1 : \를 한번씩 더 붙여서 \\로 만들기
df=pd.read_excel('C:\\Users\\user\\OneDrive\\Desktop\\marketing\\NAVER.xls')
# 방법2 : \를 /로 다 바꿔주기
df=pd.read_excel('C:/Users/user/OneDrive/Desktop/marketing/NAVER.xls')
# 방법3 : 앞에 r 붙여주기
df=pd.read_excel(r'C:\Users\user\OneDrive\Desktop\marketing\NAVER.xls')그렇게 데이터를 불러오면

위와 같이 row 0에 column 명이
들어가있다. 즉, 첫번째 row을
('캠페인보고서 ~~~'가 적혀있는 줄)
지우고 싶으면 skiprows 함수를
사용하여 불필요한 행을 제거하면 된다.
# 첫 행 삭제
df=pd.read_excel('C:/Users/user/OneDrive/Desktop/marketing/NAVER.xls', skiprows=[0])
# 어러 행 삭제
df=pd.read_excel('C:/Users/user/OneDrive/Desktop/marketing/NAVER.xls', skiprows=[1,5,6])
df=pd.read_excel('C:/Users/user/OneDrive/Desktop/marketing/NAVER.xls', skiprows=[1:9])
데이터를 불러왔으면
df.isnull()을 활용하여 결측치를
확인할 수 있는데 단순히 isnull만
입력해서 출력되는 값을 보면
보기가 힘드니까 sum함수를 이용하여
열단위 결측치 확인을 할 수 있다.
# 결측치 확인 - 열 단위
df.isnull.sum()
# 결측치 확인 - 행 단위
df.isnull.sum(axis=1)데이터 소수점 아래 값 정리하기

결측치가 없다는 것을 확인하고 나서는
클릭수와 같이 1단위임에도 소수점이
붙은 데이터를 round함수를 이용하여
정리해준다.
clk = round(df['클릭수'], 0)잊어버렸을까봐 간단히 review하자면
일의 자리=0 을 기준으로 반올림을
하는 함수로 위와 같이 0이면
1의 자리 '까지' 나타내는 것이다.
간단하다. 뒤에 1,2,3이 오면 소수점
아래 1,2,3번째까지 표현하라는 것.
소수점 제거 방법
clk.astype(int)이제는 필요 없어진 소수점을
제거해줄 차례인데 소수점을 제거한다는
것은 데이터 타입을 실수(float)에서
정수(int)로 변경하겠다는 것이다.
# 기존 칼럼 대체
df['클릭수']=clk.astype(int)
# 동일한 방식으로 평균클릭비용(VAT포함,원) 값 정리
cpc = round(df['평균클릭비용(VAT포함,원)'], 0)
df['평균클릭비용(VAT포함,원)'] = cpc.astype(int)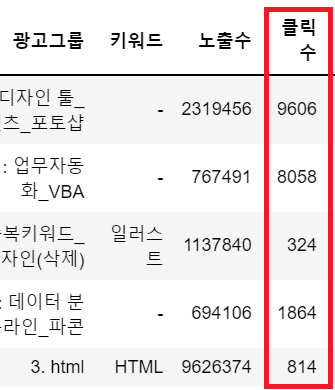
이렇게 클릭수가 바뀌었기 때문에
이전에 살펴보았던 광고 지표 중 하나인
클릭률도 바뀌었을 것으로 예상된다.
그것을 살펴보겠다.
df['클릭률(%)'] = df['클릭수'] / df['노출수'] * 100파이썬에서는 데이터프레임의 열끼리도
수치 연산이 가능하기 때문에 위와 같은
코딩이 가능하다.
데이터 탐색 with Pandas
head() 함수는 이미 알고 있다시피
데이터의 첫 부분 출력하는 것으로
default값은 첫 5개 행이다.
처음에 이것을 하는 이유는 데이터의
구성, 칼럼명 등 대략적인 데이터를
파악하기 위해서이다.
만약 n줄을 출력하고 싶으면
df.head(n)이라고 입력하면 된다.
df.tail()
df.tail(n)데이터의 끝부분을 출력하는
tail() 함수도 마찬가지이다.
df.shapeshape함수는 dataframe의 크기를
- 행, 열의 수- 출력해준다. 주의할 건
df.shape() 이 아니라 df.shape 란 거다.
(괄호)가 붙지 않는다.
df.describe()describe()함수도 자주 쓰이는 함수 중
하나로 각 열에 대한 기술통계량을 출력해준다.

데이터의 수, 평균, 표준편차, 최소값, 1사분위수,
2사분위수, 3사분위수, 최대값이 출력된다.
** Exponential Notation, 10**n
저 표에서 e+n 은 지수 표기법
이라고 하여 10의 제곱승을 뜻한다.
예를 들어 1.381000e+03 = 1.381000×10³
다음은 pandas출력 옵션설정이다.
pd.set_option('display.float_format', '{:.2f}'.format)항상 float 형식으로 수치가표기되도록
하고, 소수점 둘째자리까지 표시
하겠다는 코드이다.
# 칼럼명 반환
df.columns
# 열(시리즈)의 고유값 탐색
df['coumn명'].unique() # 예시 : df['키워드'].unique(), df['광고그룹'].unique()
# 고유값 목록이 너무 길어 몇 개인지 확인하고 싶을 때
len(df['coumn명'].unique())
# 열의 고유값 빈도
df['coumn명'].value_counts() # 예시 : df['광고그룹'].value_counts()
# (값)정렬 (default : 오름차순)
df['coumn명'].sort_values() # 예시 : df['노출수'].sort_values()
# (값)정렬 내림차순
df['coumn명'].sort_values(ascending=False)그외 자주 사용하는 기본적인 함수들.
'Data Science > with Python(Numpy, Pandas …ect.)' 카테고리의 다른 글
| 검색광고 데이터 분석 : 검색광고 데이터 키워드/광고그룹 분석 (0) | 2022.07.10 |
|---|---|
| [데이터분석 인강]검색광고 데이터 분석 : 데이터 탐색 시각화ver. (선그래프) (0) | 2022.07.09 |
| 마케팅 데이터 분석 : 간단한 matplotlib 사용법 정리 (0) | 2022.07.08 |
| Kaggle Survey EDA 03 : 직업과 관련된 EDA (0) | 2022.07.06 |
| Kaggle Survey EDA 02 : 교육수준과 관련된 EDA (0) | 2022.07.06 |