2022. 7. 25. 12:01ㆍSQL
인덱스의 내부 작동 원리
이전에 말했듯 인덱스가 늘 좋은 것이
아니므로 정확히 판단하여 적절히
활용하는 것이 중요하다. 이때 내부 작동
원리를 이해하고 있으면 도움이 된다.
균형 트리의 개념
'자료 구조'에 나오는 범용적으로 사용되는
데이터의 구조로 클러스터형/보조 인덱스 모두
내부적으로 균형 트리로 만들어진다.
여기서 데이터가 저장되는 공간을 노드라고 한다.
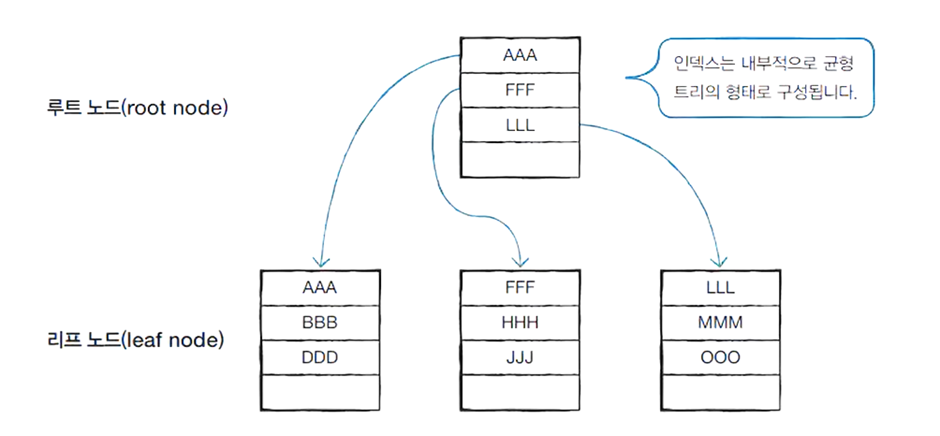
루트 노드(페이지) : 가장 상위 노드
리프 노드(페이지) : 가장 마지막 존재 노드
중간 노드(페이지) : 루트와 리프 사이의 노드들
※ MySQL에서는 페이지라고 한다.
리프 페이지만 있는 경우 찾고 싶은 정보를
처음부터 끝까지, 전체 테이블 검색 방식으로
일일히 뒤져보는 수밖에 없다. 하지만 균형트리라면
무조건 루트 페이지부터 검색을 한다. 루트에서 몇 번째
리프 페이지에 해당 정보가 있을지 검색하고 바로
해당 리프 페이지로 이동하여 찾기 시작한다.
데이터가 크면 클수록 유리해질 수밖에 없는 방식이다.
균형 트리의 페이지 변환
인덱스를 사용하면 SELECT는 빠르나
데이터 변경 작업은 느려진다.
데이터 변경 작업 : INSERT, UPDATE, DELETE

그 이유가 위와 같이 페이지 분할
작업이 발생하기 때문이다.
인덱스 구조와 데이터 검색
클러스터형 인덱스
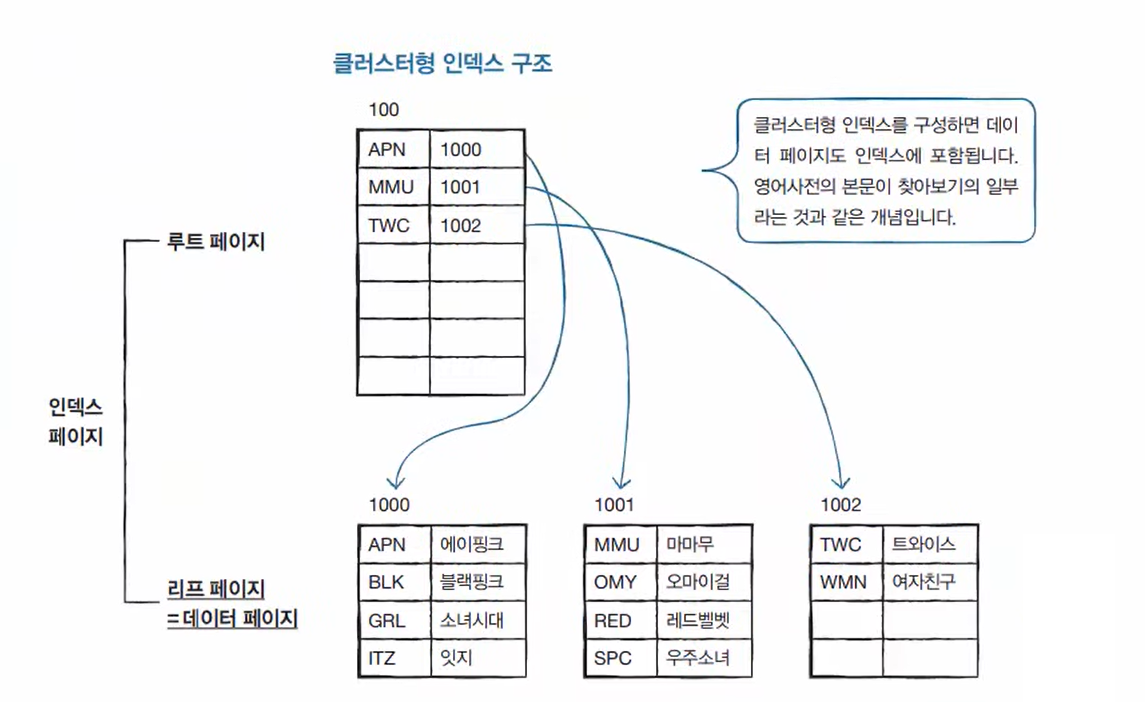
USE market_db;
CREATE TABLE cluster -- 클러스터형 테이블
( mem_id CHAR(8) ,
mem_name VARCHAR(10)
);
INSERT INTO cluster VALUES('TWC', '트와이스');
INSERT INTO cluster VALUES('BLK', '블랙핑크');
INSERT INTO cluster VALUES('WMN', '여자친구');
INSERT INTO cluster VALUES('OMY', '오마이걸');
INSERT INTO cluster VALUES('GRL', '소녀시대');
INSERT INTO cluster VALUES('ITZ', '잇지');
INSERT INTO cluster VALUES('RED', '레드벨벳');
INSERT INTO cluster VALUES('APN', '에이핑크');
INSERT INTO cluster VALUES('SPC', '우주소녀');
INSERT INTO cluster VALUES('MMU', '마마무');
SELECT * FROM cluster;
ALTER TABLE cluster
ADD CONSTRAINT
PRIMARY KEY (mem_id);
SELECT * FROM cluster;
보조 인덱스

USE market_db;
CREATE TABLE second -- 보조 인덱스 테이블
( mem_id CHAR(8) ,
mem_name VARCHAR(10)
);
INSERT INTO second VALUES('TWC', '트와이스');
INSERT INTO second VALUES('BLK', '블랙핑크');
INSERT INTO second VALUES('WMN', '여자친구');
INSERT INTO second VALUES('OMY', '오마이걸');
INSERT INTO second VALUES('GRL', '소녀시대');
INSERT INTO second VALUES('ITZ', '잇지');
INSERT INTO second VALUES('RED', '레드벨벳');
INSERT INTO second VALUES('APN', '에이핑크');
INSERT INTO second VALUES('SPC', '우주소녀');
INSERT INTO second VALUES('MMU', '마마무');
ALTER TABLE second
ADD CONSTRAINT
UNIQUE (mem_id);
SELECT * FROM second;
두 인덱스 모두 검색이 빠르다.
다만 클러스터형 인덱스가 조금 더 빨라
효율적이란 것을 알 수 있다.
'SQL' 카테고리의 다른 글
| [SQL 독학] 스토어드 프로시저의 개념과 사용법 (0) | 2022.07.26 |
|---|---|
| [SQL 독학] 인덱스 생성/제거 문법 (0) | 2022.07.25 |
| [SQL 독학] 인덱스의 개념과 종류, 장단점 (0) | 2022.07.20 |
| [SQL 독학] 가상의 테이블 : 뷰(생성, 수정, 삭제) (0) | 2022.07.19 |
| [SQL 독학] SQL 테이블 제약조건(기본키, 외래키, 고유키) (0) | 2022.06.23 |